
























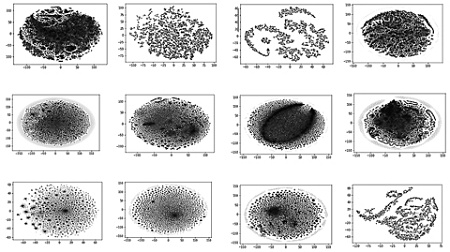
 Портреты естественных языков как целого в двумерной проекции. Крайний справа в средней строке – русский язык; слева от него – латинский; два изображения в центре верхней строки – африканские языки. Источник: иллюстрация из презентации В.А. Громова, 29 апреля 2025 года
Портреты естественных языков как целого в двумерной проекции. Крайний справа в средней строке – русский язык; слева от него – латинский; два изображения в центре верхней строки – африканские языки. Источник: иллюстрация из презентации В.А. Громова, 29 апреля 2025 года
Очередное заседание Никитского клуба (заявленная миссия НК, учрежденного в 2000 году по инициативе ученых и предпринимателей, – «объединить интеллектуальные силы России, сделать их активным ресурсом развития страны») было посвящено теме вроде бы вполне «вегетарианской»: «Вопросы языковой безопасности». Но уже краткая аннотация доклада, предложенного к обсуждению, места скуке не оставляла: «Рассмотрение естественного языка как единого целого в рамках современных подходов к моделированию сложных систем позволило в том числе установить его базовые характеристики (внутренняя размерность языка, «дырки» в языке), рассмотреть ряд вопросов функционирования языка в современном мире:
1. «Поймай бота»: различение текстов, написанных людьми и сгенерированных ботами.
2. «Машина, творящая открытия»: оценка новизны научных текстов с точки зрения пространства языка».
Автор доклада, предложенного на обсуждение, – доктор физико-математических наук, профессор департамента анализа данных и искусственного интеллекта, завлаб анализа семантики (ЛАНС) центра языковых и семантических технологий (НИУ ВШЭ) Василий Громов.
Антиплагиат отдыхает!
Если совсем кратко, то группа математиков и лингвистов под руководством Василия Громова создала геометрическую «крупнозернистую» модель языка (в идеале – любого языка). Эта сложная топологическая модель была использована для «выявления «дыр» (устойчивых гомологий) в семантических пространствах слов, биграмм и триграмм английского и русского языков, а также для установления их границ... Эти границы очерчивают «слепые пятна» соответствующего языка (области семантических пространств, которые не содержат слов/биграмм/триграмм языка, то есть области понятий, которые язык не может видеть через свою линзу)».
Прагматика здесь такова. Развитие технологий искусственного интеллекта (ИИ) привело к появлению мощных моделей языкового моделирования, способных создавать тексты, неотличимые от текстов, созданных человеком. Это создает серьезную проблему – как определить, кто является автором текста: человек или программа?
Сегодня 90% курсовых и дипломных работ в вузах РФ создаются с решающей помощью текстов, сгенерированных чат-ботами. Если для естественно-научных специальностей это еще как-то приемлемо (в них обычно довольно много обязательных стандартных языковых конструкций), то для гуманитарных дисциплин, где порождение новых смыслов (желательно принципиально новых) и есть конечный продукт, – катастрофа. По сравнению с задачей выявления некорректного заимствования (плагиата) в текстах задача установления степени «естественности» курсовых, дипломных и даже кандидатских/докторских работ на порядки более сложная.
«Нынешнее поколение детей растет на текстах, сгенерированных ботам, для ботов и сгенерированных без всякой цели, – отмечает Василий Громов. – Люди, которые вырастут на текстах, сгенерированных ботами, вырастут совсем другими людьми, чем мы». То есть бот генерирует, генерирует и генерирует тексты – это его функция, онтологическое свойство, если можно так сказать. Развивая эту мысль, неизбежно возникает вопрос: появится ли другой вид (подвид) Homo Sapiens?
Но это все-таки «лирика». А что позволил выявить созданный портрет естественных языков как целого? И, главное, как это может помочь идентифицировать текст, созданный (измысленный) человеком, и текст, созданный ботом, средствами естественного языка?
Идея простая. Некий корпус естественного языка представляет собой n-мерное векторное пространство. То есть гигантский геометрический объект с n-мерной внутренней размерностью. Язык, таким образом, в математических терминах можно определить как самоорганизующуюся критическую систему. В классе сложных самоорганизующихся систем языковые системы самые сложные. Причем языковые системы имеют лавинообразную природу. «Лавина» – это любой текст.
Любопытно, что, например, язык эсперанто не порождает таких «лавин» смыслов. Он и не является естественным, это выдуманный, сконструированный язык. И при этом на эсперанто существует большая литература, издаются СМИ, люди признаются в любви на этом языке и даже пишутся стихи. Семантическая сложность эсперанто не дотягивает до «естественности» даже самых примитивных человеческих языков.
«Все естественные языки – мультифракталы. Внутренняя размерность для естественных языков лежит между 9 и 10», – отмечает Василий Громов. И это – умопомрачительно высокая сложность. Мало того, по мнению Громова, «структура естественных языков – всех! – это, судя по всему, некая нейрофизиологическая константа».
Мы привыкли считать, что живем в трехмерном пространстве. Но добавьте координату по времени – и вы попадаете уже в четырехмерное пространство-время. Современная физика утверждает, что размерность окружающего нас мира существенно больше. (Например, в теории Калуцы физическая реальность имеет пять измерений.) И размерность процессов в головном мозге тоже.
Василий Громов в связи с этим предлагает гипотезу «Сверхузкое бутылочное горлышко»: «Когда мы пропускаем процессы в мозге через языковой канал, происходит фильтрация, размерность естественного языка – «всего» 9–10. И афоризм Тютчева «Мысль изреченная есть ложь» здесь как нельзя более точен и кстати».
Самое интересное, что выяснили исследователи, работая с такой n-мерной геометрической моделью, это то, что в языке (в этой десятимерной поверхности) есть «дырки». «То есть существуют области семантического пространства, для которых нет обозначения отдельным словом, – поясняет Громов. – Например, в русском языке – «могло бы быть». Или попробуйте слово «воля» перевести на английский! Это своеобразные «слепые пятна» языка. «Темная материя» языка. Вот этими «дырками» естественные языки и отличаются – своими «слепыми пятнами»; тем, что язык может выразить, и тем, что не может».
В этом и отличие языка людей от языка ботов! Чат-боты стараются избегать областей с «дырками». А вот в областях семантической определенности они чувствуют себя прекрасно. Но начинают «галлюцинировать» там, где в естественном языке «дырки». По-другому: человек, даже самый необразованный, всегда ищет неожиданные последовательности смыслов. «В этом отличие людей от ботов. Пока по крайней мере», – подчеркивает Василий Громов.
Именно это свойство больших лингвистических моделей (LLM) и предлагается использовать для «сепарации» текстов, созданных ботами, от текстов естественного языка. Или, как это строго формулирует Василий Громов, «…решить проблему обнаружения ботов в ее сильной постановке, то есть обучать классификаторы на одном наборе ботов и тестировать на другом наборе ботов. Для этого мы оцениваем средние расстояния от слов, биграмм и триграмм текста до границ ближайшей «дыры» для текстов, как написанных людьми, так и сгенерированных ботами, и строим классификаторы. Классификаторы показывают сравнительно хорошие результаты: средняя точность составляет 0,8».
Антропоморфный знаменатель
Идеальной точкой кристаллизации, обсужденной на заседании НК темы, возможно, была бы цитата из книги, опубликованной впервые в 1967 году: Станислав Лем, «Сумма технологии» (в оригинале – «Summa technologia»). Вот она:
«Кто кем повелевает? Технология нами или же мы – ею? Она ли ведет нас, куда ей вздумается, хоть бы и навстречу гибели, или же мы можем заставить ее покориться нашим стремлениям? И что же, если не сама технологическая мысль, определяет эти стремления? Всегда ли так обстоит дело или же само отношение «человечество – технология» меняется с ходом истории? А если так, то к чему стремится эта неизвестная величина? Кто получает превосходство, стратегическое пространство для цивилизационного маневра – человечество, свободно черпающее из арсенала технологических средств, которыми оно располагает, или же технология, которая увенчивает автоматизацией процесс изгнания человека из своих владений? Существуют ли технологии, которые мыслимы, но неосуществимы ни сейчас, ни когда-либо вообще? И что же тогда предрешает эту неосуществимость: структура природы или наша ограниченность? Существует ли другой – нетехнологический – путь развития цивилизации? Типичен ли наш путь для Космоса, что составляет он – норму или отклонение?»
Философические снобы (подчеркнем: это отнюдь не негативная коннотация; скорее популяционное определение вида по ареолу обитания), конечно, скажут: «Лем? Ну, это несерьезно… Вот Кьеркегор, Витгенштейн, на худой конец Хайдеггер. Это авторитетно».
Почему-то изложение экзистенциональных пропозиций узнаваемым языком считается философским моветоном. Канонический пример, опровергающий правомерность такой эпистемологической позиции, – случай Айзека Азимова, химика, популяризатора науки и писателя-фантаста. Сугубо фантастический (fiction) текст становится частью строго научного дискурса. Так произошло, например, с тремя законами роботехники, впервые сформулированными Азимовым в фантастическом рассказе «Хоровод» (1942):
«1. Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинен вред.
2. Робот должен повиноваться командам, которые ему дает человек, кроме тех случаев, когда эти команды противоречат Первому Закону.
3. Робот должен заботиться о своей безопасности, поскольку это не противоречит Первому и Второму законам».
Без обсуждения эвристического потенциала этой триады сегодня редко обходится какая-либо крупная международная конференция по робототехнике и системам генеративного искусственного интеллекта (ИИ). Анализу – логическому, философскому, методологическому – этих трех законов роботехники посвящен уже вполне впечатляющий корпус текстов.
Такие «неконвенциональные» авторы (добавим сюда, например, Аркадия и Бориса Стругацких etc) тем не менее и создают ресурс «мутационного давления» и на науку, и на социум в целом. Кстати, сам Станислав Лем не допускал создания «Электронного Антихриста» (концепция и термин «Искусственный интеллект» 50 лет назад были еще в эмбриональном состоянии): «... ни один Усилитель Интеллекта не станет Электронным Антихристом. Все эти мифы имеют общий антропоморфный «знаменатель».
«Можно ли будет когда-нибудь построить электронный мозг – неотличимую копию живого мозга? – Безусловно, да. Но только никто этого не будет делать, – успокаивает нас Лем. – Речь идет не о том, чтобы сконструировать синтетическое человечество, а лишь о том, чтобы открыть новую главу Технологии, главу о системах сколь угодно большой степени сложности. Если даже человек все может осуществить, то наверняка не любым способом. Он достигнет в конце концов любой цели, если только того пожелает, но, быть может, еще раньше поймет, что цена, которую придется за это заплатить, делает достижение данной цели абсурдным».
Сегодня мы можем себя уже не обманывать и совершенно отчетливо признать: человек все-таки будет (sic!) делать копию человеческого мозга. И уже делает. Заседание НК, на котором пытались «поймать бота», – вносит свой, пусть малый, вклад в эту дискуссию.
Грубозернистая семантика
В декабре 2024 года Василий Громов в составе группы ученых из НИУ ВШЭ опубликовал в издании PeerJ. Computer Science статью с уже знакомым нам названием: «Spot the bot: the inverse problems of NLP» («Найди бота: обратные задачи НЛП»).
«В статье рассматривается проблема различения текстов, написанных человеком, и текстов, сгенерированных ботом, – отмечают авторы. – В отличие от классической постановки задачи мы рассматриваем задачу различения текстов, написанных любым человеком, от текстов, сгенерированных любым ботом. Это предполагает анализ крупномасштабной, грубозернистой структуры семантического пространства языка. Мы стремимся найти эффективные и универсальные признаки, а не сложную архитектуру модели классификации, которая имеет дело только с определенным типом ботов. Масштабное моделирование показывает хорошие результаты классификации (качество классификации более 96%), хотя и различается для языков разных языковых семейств».
Итак, 4% – пространство неуловимых «ботовых» текстов. Пожалуй, никакой ВАК не сможет отследить это лингвистическое творчество ботов и обвинить соискателя ученой степени в нейросетевом плагиате. (Впрочем, в другом исследовании этот показатель составил 20% – тоже немного, но уже существенно.)
Развитие технологий искусственного интеллекта привело к появлению мощных моделей языкового моделирования, способных создавать тексты, неотличимые от человеческих. (Ну, почти неотличимые.) Это создает нетривиальную аксиологическую проблему различения авторства текстов – человек или сложноорганизованная система электрических токов?
Нейросетевые боты сегодня воспитываются, обучаются, подвергаются дрессировке подобно животным на собачьей площадке. Обучение на огромных корпусах текстов позволяет искусственному интеллекту усваивать стилистические особенности и лексику различных авторов. Языковые модели научились адаптироваться к различным жанрам и стилям письма, включая художественную литературу, научные статьи, публицистику и деловую переписку…
Неспособность (принципиальная невозможность?) отличить человеческий текст от сгенерированного («очеловеченного») ботом, помимо всего прочего, уже привела к спорам относительно авторских прав и ответственности за контент.
Так возникает эффект самоподдерживающейся цепной реакции. Кажется, все признают, что проблема различения текстов, созданных человеком и ботом, становится все более актуальной в условиях стремительного развития ИИ-технологий. Но для ее решения необходимо отыскивать нетривиальные подходы, включающие статистический анализ, лингвистическое исследование и использование технологических инноваций. А это, в свою очередь, стимулирует развитие высокотехнологичных отраслей общественного производства. В том числе и (вос)производства научного знания.
Еще один любопытный эффект, связанный с идентификацией бота. В Сети легко найти списки признаков, которые могут указывать на то, что текст сгенерирован ИИ: однородная структура предложений; отсутствие риторического разнообразия; повторение одних и тех же фраз и/или оборотов; нейтральная тональность текста, избегание индивидуальных предпочтений или чувств; несоблюдение специфики жанра или формата; ошибки согласования; неправильное употребление предлогов и союзов; недостаточная глубина аргументации; монотонность ритма; ошибочные данные или искаженная информация, особенно в специализированных областях.
Обратите внимание: все перечисленное – это требования, предъявляемые к авторам («кожаным») научных статей в рецензируемые издания. Въедливый литературный и научный редактор (а еще – и рецензенты!) могут замучить соискателя публикации до такой степени, что проще, кажется, действительно обратиться за помощью к боту. Так замыкается круг.
Но это все – технологии в общем-то. Сегодня же речь идет о «мерцании» онтологических оснований вида Homo sapiens. Чилийский биолог и философ Умберто Матурана в известной своей статье «Биология познания» (Humberto R. Maturana. Biology of Cognition. BCL Report № 90. 1970), так определял роль языка: «Посредством языка мы взаимодействуем в области описаний, оставаясь в ней необходимо даже тогда, когда делаем утверждения о вселенной или о нашем знании о ней. Эта область одновременно и конечна, и беспредельна: конечна потому, что все, что мы говорим, является описанием, а беспредельна потому, что каждое описание конституирует в нас основу для новых ориентирующих взаимодействий, а значит, и для новых описаний. Итогом такого процесса рекурсивного применения описаний является самосознание, представляющее собой новое явление в области самоописания, причем единственным его нейрофизиологическим субстратом является нейрофизиологический субстрат самого ориентирующего поведения. Таким образом, область самосознания как область рекурсивных самоописаний также конечна и беспредельна».
То есть, по Матуране, фундаментальная функция языка вовсе не коммуникация, но «ориентация ориентируемого» в его собственной когнитивной области. «В ориентирующем взаимодействии первого организма поведение как коммуникативное описание вызывает в нервной системе второго организма специфическое состояние активности. Все это ведет к порождению еще одной области взаимодействий (а значит, и дополнительного измерения когнитивной области), области взаимодействий с репрезентациями поведения (взаимодействий), включая и ориентирующие взаимодействия, как если бы эти репрезентации были независимыми сущностями внутри ниши, к порождению языковой области».
Пока еще нейронная сеть в голове Homo Sapiens на несколько порядков превосходит по сложности нейронные сети ботов. Однако успокаивать себя ощущением собственного превосходства нашему виду осталось недолго. Уже сейчас легко представить себе новый параметр социального разделения людей: те, кто способен будет генерировать новые смыслы; и те, кому достаточно будет для обеспечения своего вполне комфортного гомеостаза уметь задавать вопросы чат-боту.
Издательство Массачусетского технологического института (MIT Press) анонсировало выход книги «Designing an Intelligence» («Проектирование интеллекта»). В качестве затравки опубликована статья из будущей книги двух признанных экспертов в области искусственного интеллекта – Дэвида Сильвера и Ричарда Саттона (первый – один из авторов AlphaZero, программы, победившей чемпионов мира в шахматах и игре Го; второй – один из разработчиков метода обучения с подкреплением, за который получил премию Тьюринга). Статья называется «Welcome to the Era of Experience» («Добро пожаловать в Эру опыта»).
Сильвер и Саттон уверены, что если позволить ИИ не просто отвечать на вопросы, а накапливать собственный опыт взаимодействия с миром, ИИ сможет формировать цели, учиться на ошибках и адаптироваться к окружающей среде (то есть к человеческому социуму). Именно этого, по их мнению, не хватает сегодняшним языковым моделям вроде ChatGPT. Такие наученные собственным опытом агенты могут превзойти нынешние модели, даже те, что заявлены как «разумные» или «рассуждающие» – вроде Gemini, DeepSeek R1 или OpenAI o1. Если ИИ будет опираться не на прошлое человечества, а на собственный опыт – возможен революционный прогресс.
Кстати, по оценкам экспертов британской компании DeepMind, в случае реализации такого подхода к обучению ИИ данные, полученные ИИ из собственного опыта, многократно превзойдут по объему и полезности все, что человечество когда-либо записало в Википедии или Reddit: «Это не просто следующий шаг – это путь к настоящему сверхинтеллекту».
Опять же здесь мы сталкиваемся с экзистенциальной ситуацией, которую Айзек Азимов моделировал еще в 1976 году в повести «Двухсотлетний человек». Главный герой, морфированный андроид Эндрю, настаивает на том, чтобы его признали человеком: «Утверждалось, что свободным может быть только человек. Но мне кажется, что быть свободным может только тот, кто хочет свободы. И я хочу свободы. Нельзя отказывать в свободе тому, кто обладает сознанием, развитым в степени достаточной, чтобы воспринимать понятие свободы и желать ее».
И вывод для сведения Homo Sapiens: «Но они не способны смириться с бессмертием человека, поскольку мысль об их личной смерти переносима только потому, что это общая участь. Вот по какой причине они не хотят признать меня человеком».



